作者:手机用户2502859861 | 来源:互联网 | 2023-08-28 18:02
如今,谁也不能否认国内数据库百花齐放的现实;
之前写过一篇有关国产数据库的文章,其中介绍了:
《2020年国产数据库“元年”,争做一只迎风起飞的“飞猪”》可点击链接
文中也提到,各行业在选型数据库时,首先想到的是参考DB-ENGINES上的各类数据库排名。
也提到了一个遗憾:
“在目前国产数据库产品日新月异的当今,有没有一个国人可以参考的国产数据库排名榜,以反映各大国产数据库的综合竞争力,从而供大家在数据库选型中有所侧重点。”
目前,最具权威的国产数据库排名榜是由墨天轮社区发起
(https://www.modb.pro/dbRank),该社区数据库排行榜致力于为大家呈现最新的国产数据库流行趋势。
墨天轮社区的国产数据库排名参考了DB-ENGINES的布局风格;
大家在面对各大国产数据选型时,是一个很有借鉴意义的排名榜单。
目前是该国产数据库排名榜收录了117个数据库产品,种类涉及:
关系型、分布式、图形、时序、KV键值、宽列存储、云原生;
7类数据库产品。
下图是今年3月份的最新排名。
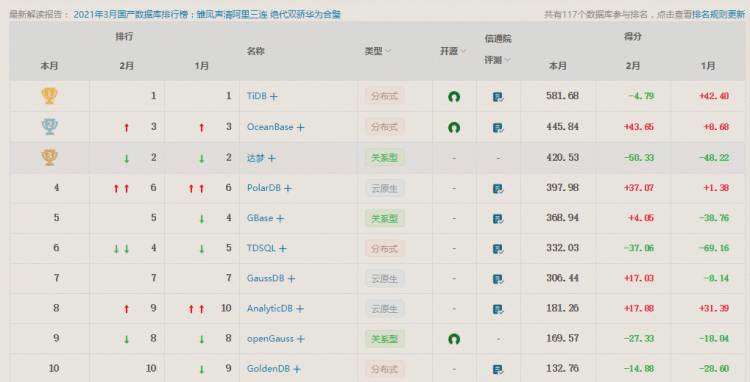
上图可以看到,目前大分数排名第一位的是分布式数据库TiDB+。
既然TiDB+ 是目前排名第一的国产数据库,那咱就认识它一番。
以下信息来自PingCAP公司官网;毕竟官方解说的最具权威性;
自己也看了下,官方解说的也明白。
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。
目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。
TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
五大核心特性
一键水平扩容或者缩容
得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
金融级高可用
数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
实时 HTAP
提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
云原生的分布式数据库
专为云而设计的分布式数据库,通过 TiDB Operator 可在公有云、私有云、混合云中实现部署工具化、自动化。
兼容 MySQL 5.7 协议和 MySQL 生态
兼容 MySQL 5.7 协议、MySQL 常用的功能、MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。提供丰富的数据迁移工具帮助应用便捷完成数据迁移。
四大核心应用场景
对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
众所周知,金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高。传统的解决方案是同城两个机房提供服务、异地一个机房提供数据容灾能力但不提供服务,此解决方案存在以下缺点:资源利用率低、维护成本高、RTO (Recovery Time Objective) 及 RPO (Recovery Point Objective) 无法真实达到企业所期望的值。TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器出现故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0。
对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如:TiDB。TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
Real-time HTAP 场景
随着 5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百 TB 甚至 PB 级别,传统的解决方案是通过 OLTP 型数据库处理在线联机交易业务,通过 ETL 工具将数据同步到 OLAP 型数据库进行数据分析,这种处理方案存在存储成本高、实时性差等多方面的问题。TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
数据汇聚、二次加工处理的场景
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比,TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
接着,再了解下TiDB 整体架构
与传统的单机数据库相比,TiDB 具有以下优势:
纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
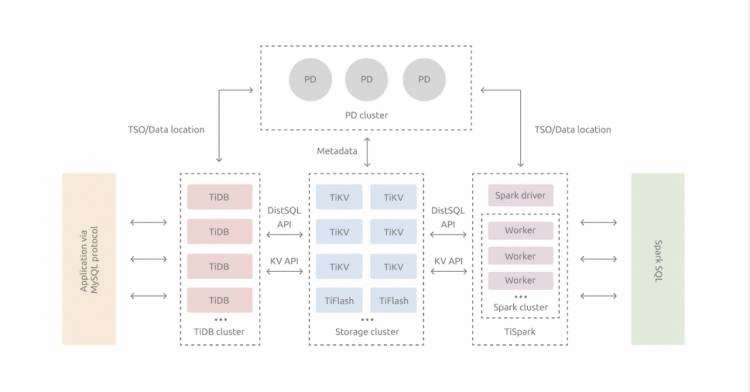
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
存储节点
TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
文章至此。
【参考】
https://docs.pingcap.com/zh/tidb/stable/overview
【参考】
https://docs.pingcap.com/zh/tidb/stable/tidb-architecture

欢迎关注个人微信公众号:
近期热文
你可能也会对以下话题感兴趣。点击链接便可查看。
为什么不建议把数据库部署在docker容器内?
排故篇 | linux环境下的oracle用户定时命令crontab任务报错不可用的原因分析和解决
汇总篇 | MySQL数据库设计开发规范
案例篇 | 记一次 MySQL 主从双写导致的数据丢失问题
技术分享 | MySQL 内存管理初探
第19问:MGR 架构,如果一个节点网络不稳,消息缓存会被撑满么?
2020年国产数据库“元年”,争做一只迎风起飞的“飞猪”
3 节点 MGR 集群,能不能将一个节点放在地球另一端?
MySQL 索引设计(索引组织方式 B+ 树)
知识篇 | 索引设计(组合索引适用场景)
MySQL 5.6 将于2021年2月停止更新!
如何在UNIX环境中运行MySQL多实例?!
MySQL性能优化(七):MySQL执行计划,真的很重要,来一起学习吧
区块链上的数据库:CovenantSQL
MySQL数据延迟跳动的问题分析
MySQL 5.6和 5.7_同步账号修改密码方式:真的不一样
MySQL8.0 为嘛弃用Query Cache?
你应该知道的分布式系统之奠基石CAP理论
MySQL数据延迟跳动的问题分析
如何判断一个应用系统性能好不好?
MySQL Document Store 混合使用关系型数据与非关系型数据
分布式一致性算法:Paxos算法学习
MySQL 中你不得不知的重要知识点
神技_如何快捷下载Oracle补丁的方法?!
趋势篇:oracle 11g,12c,18c,19c之support lifetime
Centos能不能替换RHEL?
Centos能不能替换RHEL?
年末总结_聊一聊数据库行业的“继往开来”
【干货篇】在国内外数据库百家争鸣的时代,DBA们该何去何从?
实操:12C RAC环境下的ADG同步库搭建
浅谈MySQL三种锁:全局锁、表锁和行锁






 京公网安备 11010802041100号
京公网安备 11010802041100号